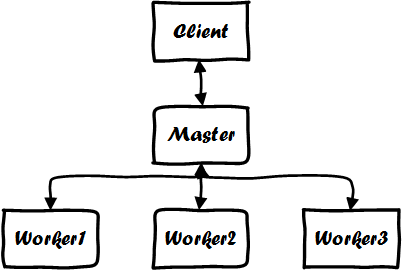
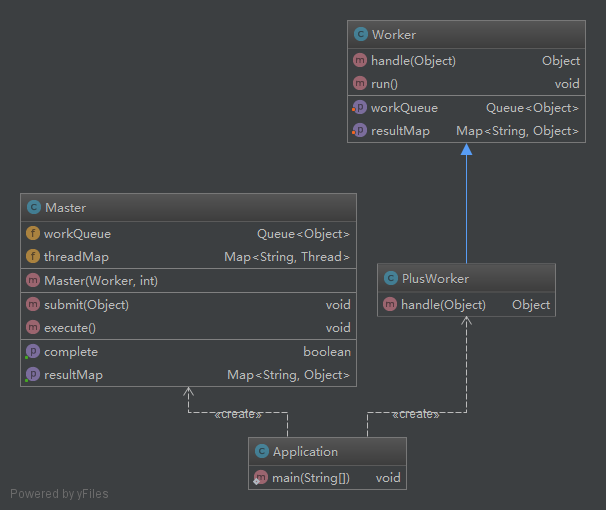
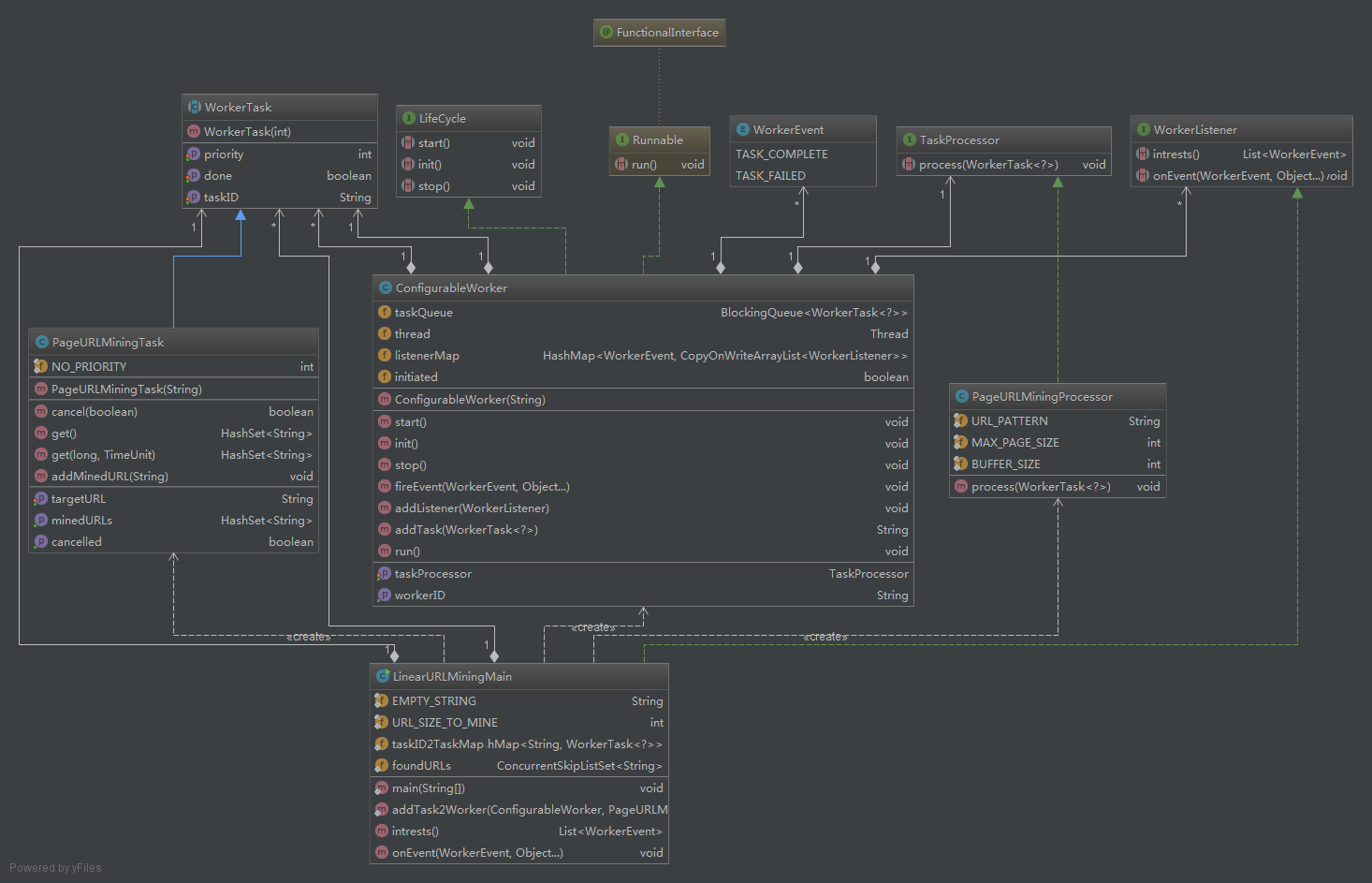
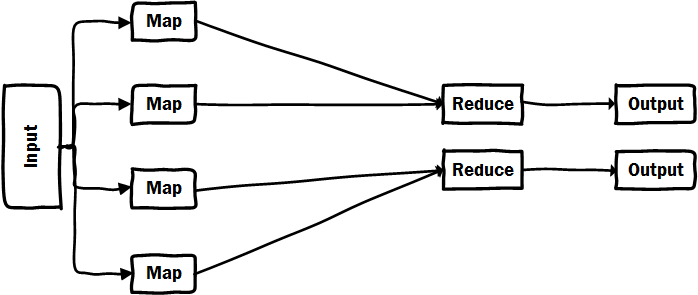
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.TreeSet;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.TimeUnit;
import com.alibaba.taobao.worker.ConfigurableWorker;
import com.alibaba.taobao.worker.SimpleURLComparator;
import com.alibaba.taobao.worker.WorkerListener;
import com.alibaba.taobao.worker.WorkerTask;
import com.majingyang.qctry.flowworker.WorkerEvent;
public class MapReduceURLMiningMain implements WorkerListener {
private static final int URL_SIZE_TO_MINE = 5000;
private static ConcurrentHashMap<String, WorkerTask<?>> taskID2TaskMap = new ConcurrentHashMap<String, WorkerTask<?>>();
private static TreeSet<String> foundURLs = new TreeSet<String>(new SimpleURLComparator());
public static void main(String[] args) throws InterruptedException {
long startTime = System.currentTimeMillis();
List<ConfigurableWorker> mappers = new ArrayList<ConfigurableWorker>(4);
ConfigurableWorker mapWorker_1 = new ConfigurableWorker("W_M1");
ConfigurableWorker mapWorker_2 = new ConfigurableWorker("W_M2");
ConfigurableWorker mapWorker_3 = new ConfigurableWorker("W_M3");
ConfigurableWorker mapWorker_4 = new ConfigurableWorker("W_M4");
mapWorker_1.setTaskProcessor(new PageContentFetchProcessor());
mapWorker_2.setTaskProcessor(new PageContentFetchProcessor());
mapWorker_3.setTaskProcessor(new PageContentFetchProcessor());
mapWorker_4.setTaskProcessor(new PageContentFetchProcessor());
mappers.add(mapWorker_1);
mappers.add(mapWorker_2);
mappers.add(mapWorker_3);
mappers.add(mapWorker_4);
ConfigurableWorker reduceWorker_1 = new ConfigurableWorker("W_R1");
reduceWorker_1.setTaskProcessor(new URLMatchingProcessor());
MapReduceURLMiningMain main = new MapReduceURLMiningMain();
reduceWorker_1.addListener(main);
addTask2Worker(mapWorker_1, new MapReducePageURLMiningTask("http://www.taobao.com"));
addTask2Worker(mapWorker_1, new MapReducePageURLMiningTask("http://www.xinhuanet.com"));
addTask2Worker(mapWorker_1, new MapReducePageURLMiningTask("http://www.zol.com.cn"));
addTask2Worker(mapWorker_1, new MapReducePageURLMiningTask("http://www.163.com"));
Map2ReduceConnector connector = new Map2ReduceConnector(Arrays.asList(reduceWorker_1));
mapWorker_1.addListener(connector);
mapWorker_2.addListener(connector);
mapWorker_3.addListener(connector);
mapWorker_4.addListener(connector);
mapWorker_1.start();
mapWorker_2.start();
mapWorker_3.start();
mapWorker_4.start();
reduceWorker_1.start();
String targetURL = "";
int lastIndex = 0;
while (foundURLs.size() < URL_SIZE_TO_MINE) {
synchronized (foundURLs) {
targetURL = foundURLs.pollFirst();
if (targetURL == null) {
foundURLs.wait();
continue;
}
}
lastIndex = ++lastIndex % mappers.size();
MapReducePageURLMiningTask task = new MapReducePageURLMiningTask(targetURL);
taskID2TaskMap.putIfAbsent(mappers.get(lastIndex).addTask(task), task);
synchronized (foundURLs) {
foundURLs.add(targetURL);
}
TimeUnit.MILLISECONDS.sleep(100);
}
mapWorker_1.stop();
mapWorker_2.stop();
mapWorker_3.stop();
mapWorker_4.stop();
reduceWorker_1.stop();
synchronized (foundURLs) {
for (String string : foundURLs) {
System.out.println(string);
}
}
System.out.println("Time Cost: " + (System.currentTimeMillis() - startTime) + "ms");
}
private static void addTask2Worker(ConfigurableWorker mapWorker_1, MapReducePageURLMiningTask task) {
String taskID = mapWorker_1.addTask(task);
taskID2TaskMap.put(taskID, task);
}
@Override
public List<WorkerEvent> intrests() {
return Arrays.asList(WorkerEvent.TASK_COMPLETE, WorkerEvent.TASK_FAILED);
}
@Override
public void onEvent(WorkerEvent event, Object... args) {
if (WorkerEvent.TASK_FAILED == event) {
System.err.println("Error while extracting URLs");
return;
}
if (WorkerEvent.TASK_COMPLETE != event)
return;
MapReducePageURLMiningTask task = (MapReducePageURLMiningTask) args[0];
if (!taskID2TaskMap.containsKey(task.getTaskID()))
return;
synchronized (foundURLs) {
foundURLs.addAll(task.getMinedURLs());
}
System.out.println("Found URL size: " + foundURLs.size());
taskID2TaskMap.remove(task.getTaskID());
synchronized (foundURLs) {
foundURLs.notifyAll();
}
}
}